This document describes a way to model discussions occurring in weblogs
and message boards using RDF, and a convention for coding weblog and message
board pages so that software can understand them at a finer grain.
Introduction
Some background to explain what a web thread is, and why you might care.
A popular style of web site organization these days is the “weblog” or
“blog”. It is a form of personal or small-group publishing comparable to—but
different from—a personal journal or newspaper column. The formatting,
organization, subject matter, tone, and style of weblogs are diverse, but
they are similar in terms of fundamental structure.
An individual weblog can be viewed as a sequence of “posts”. Each post
is typically self-contained and has its own address, but may be presented
as part of a larger “archive” containing many posts, perhaps a day’s
or month’s worth. In addition to the archives, a weblog will have a
primary page which mirrors the most recently published posts.
Weblog posts very greatly in style and content, even within a single
weblog. Some may be long essays while others are simply a reference to
something interesting in the Web and a suggestion that readers check it
out.
As weblogs became more common, authors began to refer to posts in
other authors’ weblogs, sometimes to give credit for finding an
interesting site, other times to respond to something the author had
written. These discussion threads, or “blogthreads”, are often quite
interesting, but they can be difficult to follow. Unlike a message
board or news group, weblogs do not have a central infrastructure that
allows a post to automatically be associated with other posts which
respond to it. That is to say, Person A might reference a post by
Person B, but there is no standard or widely-deployed way for other
readers of Person B’s post to learn about what Person A wrote. Person B
might refer back to Person A, but then readers of Person A’s weblog won’t
necessarily know about Person B’s response.
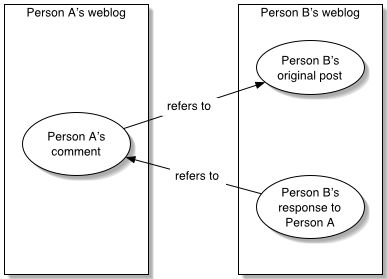
If each post links to the post it references, then it is easy to follow
the chain of references back to the beginning. The difficulty lies in following it
forward.
It is unreasonable to expect authors to insert these “forward” links
into their posts, as a post may be referenced by dozens or hundreds of
others and the author may not be aware of them. What is needed is an
automated way to gather information about blogthreads and present it
to readers. To do this, we must be able to answer these questions:
- Given a post, what posts refer to it?
- Given a page, what posts does it contain?
- Given a post, what references does it make?
If we know how to answer the second and third questions, we can gather
enough information for a partial answer to the first question. Software
can automatically scan weblogs to determine what posts exist and what
they refer to. At that point, it is simple to check which of those
posts refer to a selected post.
This document describes two important parts of such a system. The
first is a standard way to describe posts and the references they make.
The second is an HTML
coding convention for weblogs which make it simple to determine what
posts an HTML
document contains and what they refer to. It concludes with some
suggestions for how this information may be used to improve reader
experience.
The graph of posts
The universe of weblogs (sometimes called the “blogosphere”) can be
viewed as a directed graph. The nodes of the graph are posts, and the
arcs are references. This is exactly the sort of thing
RDF is designed
to model, so we will use it to describe the graph.
Each post is identified by a URI
reference (a URI
which may contain a fragment identifier). To indicate that these particular
resources are posts, we will give them the type “Post”. We will use the
property “refersTo” to indicate that a post is referring to something.
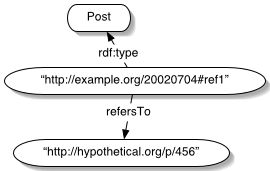
For example, to represent a post “http://example.org/20020704#ref1” which
refers to “http://hypothetical.org/p/456”, we have:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns="http://www.eyrie.org/~zednenem/2002/web-threads/">
<Post rdf:about="http://example.org/20020704#ref1">
<refersTo rdf:resource="http://hypothetical.org/p/456"/>
</Post>
</rdf:RDF>
The first three lines indicate that this is
RDF, that
elements with a “rdf:” prefix belong to the core
RDF namespace,
and that elements with no prefix belong to the namespace defined by this
document.
The next few lines indicate that we are talking about the resource
“http://example.org/20020704#ref1”, that is has the type “Post”, and
that it has a “refersTo” relationship to the resource
“http://hypothetical.org/p/456”. Because
RDF is based
on labelled arcs, we represent the type information as an “rdf:type”
arc between the post and the class “Post”. (Because “Post” is part of
the namespace “http://www.eyrie.org/~zednenem/2002/web-threads/”, it
can be referenced by the URI
“http://www.eyrie.org/~zednenem/2002/web-threads/Post”. For the sake of
brevity, we will continue calling it “Post”.)
The ability to indicate that a post refers to some resource is all
that is necessary for threading. In fact, it allows for threads
whose structures are far more complex than those found in typical
message boards. A given post may refer to multiple posts earlier
in the thread, which may create ambiguity when presenting an overview
of the thread to a reader.
The exact algorithm used to present the graph of posts in terms of
discussion threads will most likely vary among applications. Providing
a list of posts which refer to a given post is fairly straightforward.
Arranging a set of interlinked posts into a forked or linear thread
can be far more complex. Application designers are free to choose an
algorithm that suits their needs and preferences, although the methods
used by Usenet news readers seem like a good starting point.
Specifying the nature of the reference
While all references can be treated the same in terms of creating
a thread, it will be useful for some applications to be able to say
more about the nature of the reference a post has made. Thus, we
define a few sub-properties of “refersTo” to indicate common
types of references made in weblogs.
- followsUp
- This post corrects or provides new information on the subject
discussed in the referenced post.
- commentsOn
- This post comments on or responds to the ideas presented in
the referenced resource.
- agreesWith
- This post agrees with or amplifies the ideas presented in the
referenced resource. (Sub-property of commentsOn)
- disagreesWith
- This post rebuts or presents evidence contrary to the ideas
presented in the referenced resource. (Sub-property of commentsOn)
- pointsTo
- This post refers to but does not discuss the referenced resource.
- quotes
- This post quotes part of the referenced resource.
All software using the web-threading vocabulary should be at least
aware of these relations, if only to be able to infer that a post which,
for example, agrees with another post also refers to it. Applications
which use the graph to present “forward” links might choose to distinguish
between types of reference with icons or colors.
For expressiveness, each of the seven reference types has an inverse.
That is to say, if post A refers to post B, then we can also say that
post B is referred to by post A.

In terms of the example from the previous section, where
“http://example.org/20020704#ref1” referred to “http://hypothetical.org/p/456”,
we have:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns="http://www.eyrie.org/~zednenem/2002/web-threads/">
<rdf:Description rdf:about="http://hypothetical.org/p/456">
<referredToBy rdf:resource="http://example.org/20020704#ref1"/>
</rdf:Description>
</rdf:RDF>
By using “rdf:Description”, this example does not specify the type of
“http://hypothetical.org/p/456”. This is just to illustrate that any
resource can have an inverse reference property; the resource
indicated as making the reference is a post.
The seven inverse reference properties are “referredToBy”, “followedUpBy”,
“commentedOnBy”, “agreedWithBy”, “disagreedWithBy”, “pointedToBy”, and
“quotedBy”.
| Property | Inverse |
|---|
| refersTo | referredToBy |
| followsUp | followedUpBy |
| commentsOn | referredToBy |
| agreesWith | agreedWithBy |
| disagreesWith | disagreedWithBy |
| pointsTo | pointedToBy |
| quotes | quotedBy |
Using the graph
The purpose of modelling the references made by posts is to use it in
some fashion. It was the desire for better user-interface for weblog discussion
threads which lead to the model and coding
convention described earlier, but they have been designed to restrict
possible applications as little as possible.
What follows are only some possible uses for this information.
Show responses to a post
Although links between two resources are conceptually bi-directional,
their implementation is not. Post A may refer to post B, but post B will
not automatically indicate the reference from post A. By collecting
information about what references made by posts, it is possible to
create a list of posts which refer to a given resource. There are several
ways that such a list might be generated and presented to a user.
In the weblog
After a post, a weblogs could include links to posts which refer to
it. Message boards do this already, indicating the responses to a given
post, but they limit themselves to responses within the message board.
These links would presumably be inserted by a content management
system.
Back-references inserted in this fashion are visible to all readers,
but only on weblogs or message boards which include the links. Readers
have no control over what links are shown or how they are presented.
Through a mediator
If a weblog or message board follows a defined coding convention,
then it’s possible for third-party services to add this functionality
to pages. An organization could offer a service so that the page
“http://thread.org/insert/http://example.org/blog/456” consists of
a copy of “http://example.org/blog/456” with information and links
appended after each post.
This works on any weblog or message board which follows a coding
convention, but the links will only be seen by people using the
mediator. Even so, this is probably the fastest way to get wide-spread
availability of the reference information. Readers have some
control over what links are shown or how they are presented, in that
they can choose which mediation service to use.
Crit is an example of a working mediation
service, although not one oriented towards this form of web threading.
In the browser
Where third-party mediation is possible, it is also possible for
information to be inserted directly by the user agent. This method
potentially provides the best user experience, because links can
be presented in ways impossible to describe with
HTML and style
sheets. Possible methods include listing posts in sidebars, or through
contextual menus. Filtering and ranking can be performed locally,
allowing for extensive customization without the scaling problems
a mediation service used by hundreds would experience.
This provides the most flexibility for readers, but it obviously
will be some time before new or modified user-agents come along.
Show overview of a thread
Presenting the links leading to and coming from a post is useful,
but there are many cases when a higher-level view of a discussion
is necessary. For example, it’s more convenient to skip to the
beginning of a thread than to follow the thread backwards if one
is coming to the discussion late.
As with the previous example, thread overviews can be provided
by different parties. Web-based overview services will be the
most accessible, but client-side software will provide more powerful
ways of displaying the thread. The number of relationships between
posts in a thread can be quite large, particularly in a message
board, which can easily provide two axes for organizing posts:
conversationally using refersTo, referredToBy, and their relatives,
and chronologically using next and prev.
More granular search engines and indices
Current search engines and services such as Blogdex
can identify the destinations of links, but cannot easily determine
their sources in a fine-grained manner. Google,
reading an archive, can only say that the links came from the archive page.
It cannot say which post they came from—it doesn’t even know that posts are
involved. When posts are mirrored on a weblog’s front page, Google indexes
them as part of the front page, even though they may be present there only
briefly.
Similarly, Blogdex reads the front pages of many weblogs to see what
resources are being referenced by many authors, but all it can say about
each reference is the weblog it came from; it cannot link to the post which
made the reference, because it has no way of knowing.
In both these cases, coding conventions such as the one described here
would allow these services to see web pages in a finer-grained manner.