Monads over indexed types
In my last two technical posts in this series, I discussed free applicative functors and Prompt monads. In the latter, I showed that Prompt monads are “free”, and that because they’re free, Prompt is a monad in the category of indexed types. Naturally, the question arises: do free applicative functors also lead to monads?
Let’s define a category A of applicative functors and applicative morphisms. That is, functions t :: f :-> g such that,
f (pure a) = pure a
f (x <*> y) = f x <*> f yAgain, we can define a forgetful functor U' : A → I. The implementations Free, C1, and C2, correspond to left adjoints of U', which means they’re all instances of IMonad.
This page is literate Haskell, so feel free to copy and paste into a *.lhs file and load it up in GHCi. You’ll also need to save the FreeApp post, or download its source. The source for this article is also available.
> {-# LANGUAGE RankNTypes, GADTs, TypeOperators #-}
>
> module FreeApp2 where
>
> import Control.Applicative
> import FreeAppFor the sake of being somewhat self-contained, here are the definitions of IMonad and friends.
> type p :-> q = forall i. p i -> q i
>
> class IFunctor f where
> imap :: (p :-> q) -> (f p :-> f q)
>
> class IFunctor f => IMonad f where
> iskip :: p :-> f p
> iextend :: (p :-> f q) -> (f p :-> f q)
>
> (?>=) :: IMonad f => f p i -> (p :-> f q) -> f q i
> m ?>= f = iextend f mRecall the definition of Free:
data Free f a where
Pure :: a -> Free f a
App :: f a -> Free f (a -> b) -> Free f bThe IFunctor instance is straightforward:
> instance IFunctor Free where
> imap f (Pure x) = Pure x
> imap f (App x xs) = App (f x) (imap f xs)In the IMonad instance, iskip is just liftFree. We could define iextend in terms of lowerFree and imap, but let’s define a more general operation instead.
> instance IMonad Free where
> iskip x = App x (Pure id)
> iextend = runFree
>
> runFree :: Applicative g => (f :-> g) -> Free f a -> g a
> runFree f (Pure a) = pure a
> runFree f (App x xs) = f x <**> runFree f xsNote that runFree maps an index-preserving function to an applicative morphism. Its inverse is (. iskip).
C1
My C1 and C2 implementations both rely on CSeq, which represents a sequence of effects.
data CSeq f a where
CNil :: CSeq f ()
CCons :: f a -> CSeq f u -> CSeq f (a,u)As with Free, this is clearly an instance of IFunctor.
> instance IFunctor CSeq where
> imap f CNil = CNil
> imap f (CCons x xs) = CCons (f x) (imap f xs)We’ll also generalize reduce slightly1 by defining:
runCSeq f = reduce . imap f> runCSeq :: Applicative g => (f :-> g) -> CSeq f u -> g u
> runCSeq f CNil = pure ()
> runCSeq f (CCons x xs) = (,) <$> f x <*> runCSeq f xsUsing this, we can easily define the IFunctor and IMonad instances of C1:
data C1 f a = forall u. C1 (u -> a) (CSeq f u)> runC1 :: Applicative g => (f :-> g) -> C1 f a -> g a
> runC1 t (C1 f x) = f <$> runCSeq t x
>
> instance IFunctor C1 where
> imap g (C1 f x) = C1 f (imap g x)
>
> instance IMonad C1 where
> iskip a = C1 fst (CCons a CNil)
> iextend = runC1C2
Again, we can use runCSeq to easily define runC2, which we will use for iextend.
newtype C2 f a = C2
{ unC2 :: forall u y z.
(forall x. (x -> y) -> CSeq f x -> z) ->
(u -> a -> y) ->
CSeq f u -> z }> runC2 :: Applicative g => (f :-> g) -> C2 f a -> g a
> runC2 t x
> = unC2 x (\f s -> f <$> runCSeq t s) (const id) CNil
>
> instance IMonad C2 where
> iskip a = C2 (\k f s -> k (\(a,s) -> f s a) (CCons a s))
> iextend = runC2The necessary instance for IFunctor is a little more difficult. The problem is that C2 takes a CSeq f as an argument and passes one to its continuation. So, x will be expecting a CSeq f, but imap f x will receive a CSeq g, and we don’t have any way to translate.
Fortunately, we can get around this by passing an empty sequence to x and then appending the input sequence to the sequence x passes to its continuation. We can do this because instances of C2 never examines the input sequence.
Thus:
> instance IFunctor C2 where
> imap g x = C2 (\k f s ->
> unC2 x
> (\f' s' ->
> rebaseC1 (imap g s') k
> (\v u -> f v (f' u)) s)
> (const id)
> CNil)It’s possible to save a traversal here by defining a variant of rebaseC1 that merges in an imap, but I’ll refrain.
Faster Free Applicative Functors
Sometime after I posted my original fast free applicatives, I came up with yet another implementation idea. C2 improved on C1 by replacing the tail of the sequence with a variable, similar to replacing [a] with [a] -> [a]. But another way of representing lists involves replacing [a] with its Church representation:
forall b. (a -> b -> b) -> b -> bThat is, the arguments to foldr.
We try the same thing for CSeq. First, its fold:
> foldCSeq :: (forall a u. f a -> p u -> p (a,u)) ->
> p () ->
> CSeq f u -> p u
> foldCSeq cons nil (CCons x xs) = cons x (foldCSeq cons nil xs)
> foldCSeq cons nil CNil = nilUnlike foldr, foldCSeq has to work with a GADT. This makes the types a little more complicated. Our return type, p can be anything, as long as we can define an appropriate cons function. For example, p could be Const Integer and our cons can add one.
> size :: CSeq f a -> Integer
> size = getConst .
> foldCSeq (\_ -> Const . (+1) . getConst) (Const 0)We’ll be seeing a lot of things with the same type as that cons argument, so let’s define an alias:
> type Build f p = forall a u. f a -> p u -> p (a,u)My first attempt to use this was a variation of C1. The most obvious implementation would simply replace CSeq f u with its encoding:
data B0 f a = forall u.
B0 (a -> u) (forall p. Build f p -> p () -> p u)But that would still need something like reduceC1, since the sequence is implicitly terminated by the p () argument. So instead, I chose to leave the sequence tail abstract, as in C2.
> newtype B1 f a = B1 { unB1 :: forall p u z.
> (forall v. (v -> a) -> p v -> z) ->
> Build f p -> p u -> z }
>
> runB1 :: Applicative g => (f :-> g) -> B1 f a -> g a
> runB1 f x = unB1 x fmap (liftA2 (,) . f) (pure ())
>
> convB1C1 :: B1 f a -> C1 f a
> convB1C1 x = unB1 x C1 CCons CNilAs the definition of convB1C1 suggests, B1 is essentially C1 with all its constructors made abstract. In fact, under normal use, B1 will never actually construct a CSeq.
Most of the instances are fairly simple.
> instance Functor (B1 f) where
> fmap f x = B1 (\k -> unB1 x (\g -> k (f . g)))
>
> instance IFunctor B1 where
> imap t x = B1 (\k cons -> unB1 x k (cons . t))
>
> instance IMonad B1 where
> iskip x = B1 (\k c n -> k fst (c x n))
> iextend = runB1As with C2, the challenge is in the definition of x <*> y, where we must somehow pass the result of y to x. With C2, we had an extra type parameter that we could use to smuggle the result in, and the same is true here: we can hide the extra value by changing p.
P a p augments an abstract sequence p with an extra parameter that extracts a value of type a.
> data P a p u = P (u -> a) (p u)
>
> consP :: Build f p -> Build f (P a p)
> consP c x (P f xs) = P (f . snd) (c x xs)Using it, we can define the Applicative instance like so:
> instance Applicative (B1 f) where
> pure a = B1 (\k c n -> k (const a) n)
>
> x <*> y = B1 (\k c n ->
> unB1 y
> (\f pu ->
> unB1 x
> (\g (P h pv) -> k (\v -> g v (h v)) pv)
> (consP c)
> (P f pu))
> c
> n)Like C2, B1 avoids recursion entirely in its definitions. Unfortunately, it duplicates work. As you can see, in the section \v -> g v (h v), the tuple generated by the effect sequence must be passed to x and y, each of which will filter out the portion that does not apply to them. Since <*> is the primary operation for applicatives, this bodes poorly for performance.
B2
Instead of abstracting CCons in C1, we could also abstract it in C2. This gives us another possible implementation:
> newtype B2 f a = B2 { unB2 :: forall p u y z.
> Build f p ->
> (forall x. (x -> y) -> p x -> z) ->
> (u -> a -> y) -> p u -> z }
>
> runB2 :: Applicative g =>
> (forall a. f a -> g a) -> B2 f a -> g a
> runB2 f x
> = unB2 x (liftA2 (,) . f) fmap (const id) (pure ())
>
> instance Functor (B2 f) where
> fmap g x = B2 (\c k f -> unB2 x c k (\s -> f s . g))
>
> instance Applicative (B2 f) where
> pure a = B2 (\_ k f -> k (flip f a))
>
> x <*> y = B2 (\c k f ->
> unB2 y c (unB2 x c k) (\s a g -> f s (g a)))
>
> instance IFunctor B2 where
> imap t x = B2 (\cons -> unB2 x (cons . t))
>
> instance IMonad B2 where
> iskip x = B2 (\c k f pu -> k (\(a,s) -> f s a) (c x pu))
> iextend = runB2Aside from the extra c parameters, the only differences between C2 and B2 are in imap and runB2, both of which take advantage of the fact that c can be any appropriately-typed function, not just CCons.
Performance
So how does the B-series compare with the C-series? As before, I used Criterion to time the various implementations traversing balanced trees of various sizes.
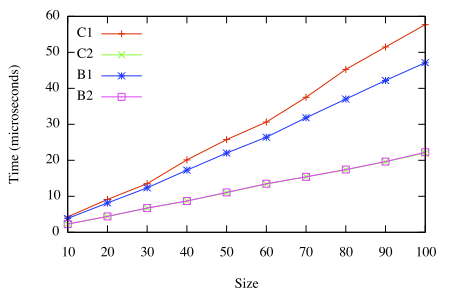
Time to traverse a tree of n elements
The results show B1 beating C1, with C2 and B2 better than both.
Comparisons of C2 and B2 are less clear. The initial tests I ran last month gave an edge to B2 of about 2 μs for n=100, but the tests I ran today show C2 faster by 0.2 μs. There are too many variables to know what caused the difference, so for now I’ll declare their performance “about the same”.2
Since the main area where B2 improves on C2 is the implementation of imap and runX, I tried the same experiment again with the addition of a single imap id after the sequenceA. Here, the results do favor B2:
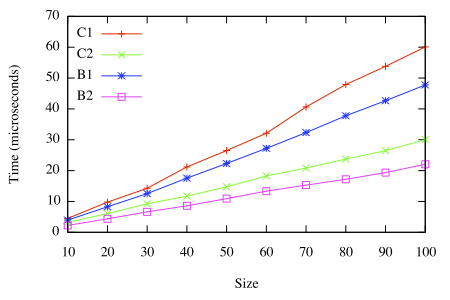
Time to traverse a tree of n elements and call imap
At n=100, B2 stays at about 22 μs, but C2 jumps to 30 μs. This suggests that B2 is definitely preferable for code using imap, and since it isn’t much worse (if at all) in other code, it suggests that B2 should be preferred in general.